2020年11月25日上午,厦大经济学科计量经济学与统计学“邹至庄讲座”系列第六讲如约开讲,清华大学统计学研究中心杨立坚教授带来题为“Statistical Inference for the Mean Function of Stationary Functional Time Series”的报告。四百余名校内外师生通过线上线下方式聆听报告。讲座由王亚南经济研究院(WISE)助理教授宋伟主持。

杨立坚教授首先回顾了函数型数据分析(Functional Data Analysis, FDA)领域已有的书籍与研究成果:Ramsay and Silverman (2002, 2005), Ferraty and Vieu (2006)等,并介绍自己在FDA的研究领域主要集中在利用同时置信带(Simultaneous Confidence Band, SCB)进行统计推断。杨教授提到统计推断的两个重要要素是假设检验和置信区间,由于FDA的研究对象不再是传统的参数或者参数向量,而是函数曲线或者曲面,应用于此类研究一个方便的工具就是SCB。

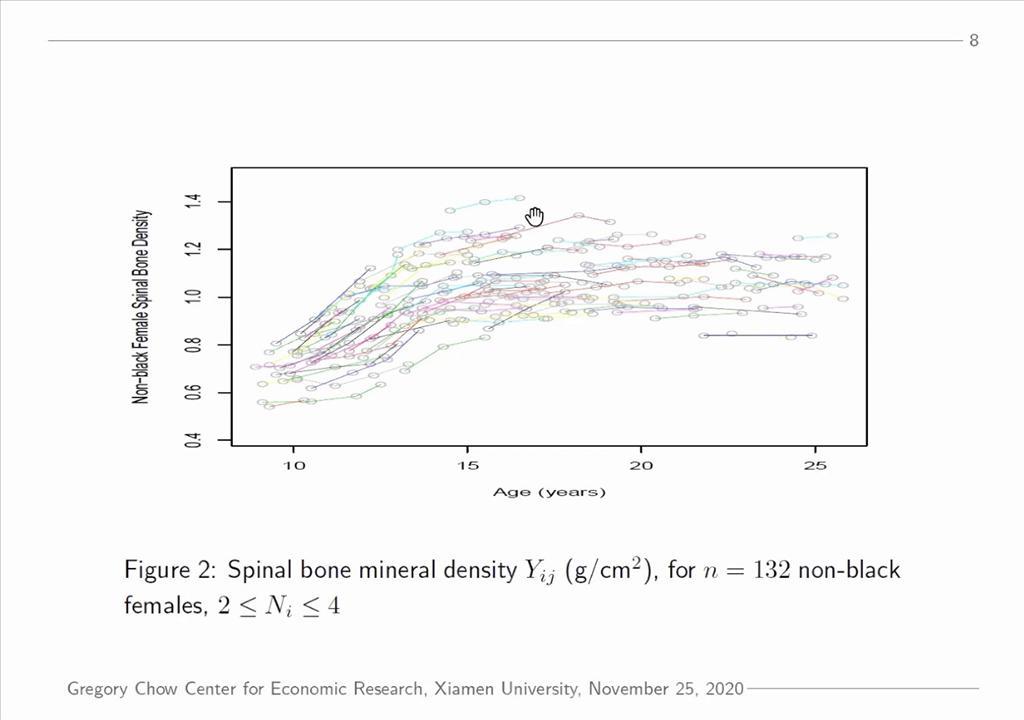
为了进一步学习函数型数据分析方法,杨教授详细介绍了FDA的原始数据。不同于传统统计分析,FDA的原始数据是由n组数据组成,其中每组数据有N次观测值,且每组观测值生成一个轨迹函数。学术界根据每组观测值数量的大小将原始观测数据分为两类:稀疏型(Sparse)和稠密型(Dense)。稀疏型数据指每组数据观测次数N有一个确定的上界,并且观测值之间独立同分布;稠密型数据是指每组数据观测次数N趋近于无穷。接着,杨教授具体介绍了几个典型的稀疏型数据研究案例:1. 对于46个HIV患者血液中的CD4细胞个数随访,每个患者随访次数为4到10次,研究生长曲线;2. 收集132位非黑人女性骨密度数据,每个人测试2到4次。稠密型数据的研究案例:240个样本的光谱吸收度监测,每个样本检测次数为100。
随后,为了对函数时间序列中不可观测随机过程的期望m函数进行估计,杨教授介绍了两步估计法:第一步对每一组数据的轨迹函数进行估计,第二步将估计到的所有轨迹函数取平均得到估计的m函数,利用估计的m函数即可计算出同时置信带。经过估计得出了两个重要结论:一是函数型中心极限定理,二是两步估计结果与样本均值估计具有等价性。另外,在模型的假设中,杨教授的研究拓宽了假设条件,误差项不必严格服从正态分布,只要满足相应的矩条件即可。
杨教授还结合研究案例讲解,对稠密型脑电数据进行研究,经过估计得到的m函数位于95%置信度的SCB之间。值得注意的是,估计结果中m函数的形状与三角函数非常相似,并在研究中利用SCB进行了检验,经过检验,三角函数的原假设在很高的置信度水平上位于同时置信区间,证明了估计得到的m函数的确是一种三角函数型。
最后,杨教授介绍了下一步研究方向:交叉自协方差函数估计,并向大家推荐了一些重要的研究参考文献。在问答环节,线上线下听讲的师生们积极提问,杨教授进一步讨论了FDA的应用领域,例如音频、光谱以及医学等,并对FDA未来在上市公司股票价格走向等方面的研究进行了展望。
(经济学院2019级博士生 梁佩凤)